產業組織 HDMI論壇在2013年9月4日正式發表最新版 HDMI 2.0 規格,新版規格能向下相容舊版的 HDMI 規格,頻寬提升至 18Gbps ,並添加許多增強功能,以支援市場對提升消費者影音體驗的持續需求。
新的HDMI 2.0功能包括:支援 4K@50/60 (2160p)解析度,提供多維式身歷其境的音訊體驗,最多可達 32 個音訊通道,音訊取樣率最高可達 1536kHz;支援雙顯示,能在同一個螢幕上同步遞送雙視訊串流給多位使用者,支援同步遞送多串流音訊給多位使用者(最多4人 )。
HDMI 2.0亦支援21:9劇院級廣角視訊,以及可透過單一搖控器控制多款HDMI裝置的CEC擴充功能;此外「動態自動對嘴同步(Lip-Sync)」技術,則能避免因視訊處理時間差異而導致的影音時間延遲問題,在無需使用者介入的模式下以動態方式同步影音串流。
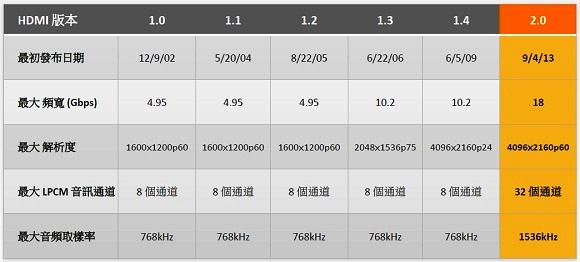
HDMI新舊規格比較
代理HDMI論壇負責HDMI技術授權業務的HDMI Licensing總裁 Steve Venuti 表示,全新的HDMI 2.0功能採用現有纜線、連接器插座/接頭就可支援,高速纜線(Category 2)纜線即可支援最大18Gbps的HDMI 2.0頻寬;能以原有纜線支援新版功能的主要原因,是新規格採用新的信令技術,提高了訊號的傳輸效率。
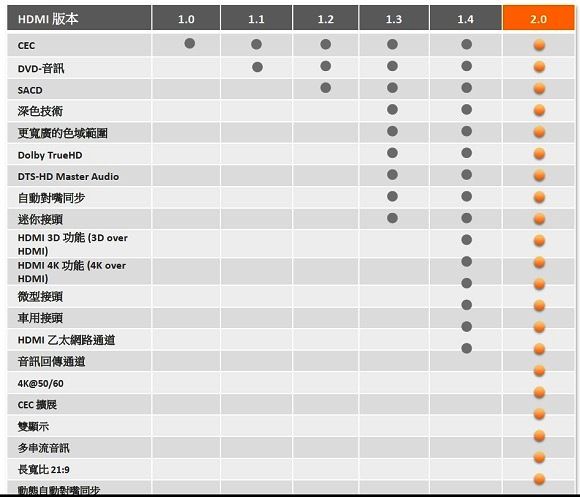
HDMI 2.0新增規格
Venuti指出,HDMI 2.0版自即日起可開放授權給HDMI裝置開發廠商,無須支付額外年費或使用費(royalty),僅須就現有的HDMI開發廠商協議簽署一份附加條款。而根據以往規格演進歷史估算,第一批採用HDMI 2.0的終端產品最快在3~6個月內就會問世;他預期在2014年初的國際消費性電子展(CES)上,就可看到廠商展示一系列相關產品。
特別來台宣傳新版HDMI規格的Venuti也歡迎更多廠商加入HDMI 論壇;他表示,HDMI原先是由HDMI聯盟7家創始會員所訂定,在2009年6月發表1.4b版規格後,創始成員認為需要有更多產業界的力量參與該規格的開發,於是在2011年10月又成立了HDMI論壇。
該論壇為非營利組織,目前成員有88名,涵蓋消費性電子產品、個人電腦、測試設備、纜線與半導體等供應商;旗下有技術與行銷兩大工作團隊,由11名成員組成的董事會負責管理。Venuti表示,只要繳交會員年費,任何組織機構皆可加入HDMI論壇,無須為現有HDMI開發廠商,論壇鼓勵更多產業界人員投入規格開發,為規格打造健全、互通的生態系統。
http://www.eettaiwan.com/ART_8800689911_480702_NT_ed9dee59.HTM